Unser Szenario
Eine gute Nachricht vorab: als Daumenregel lässt sich festhalten, dass performante Algorithmen normalerweise auch die energiesparenderen sind. Komplizierter wird es jedoch, wenn Parallelisierung ins Spiel kommt. Wir wollten es genauer wissen und haben uns ein Test-Setup überlegt.
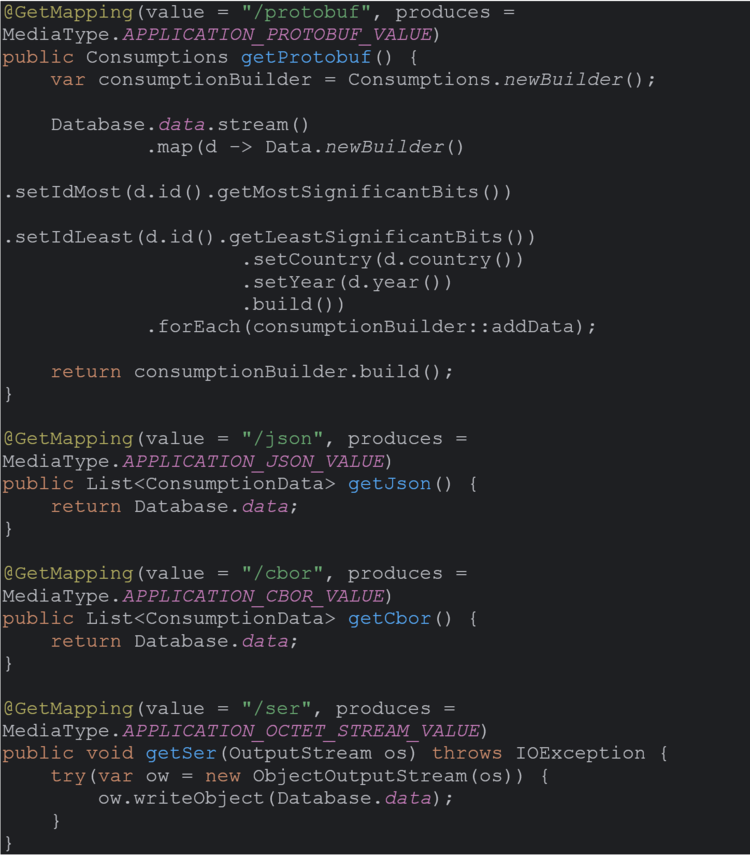
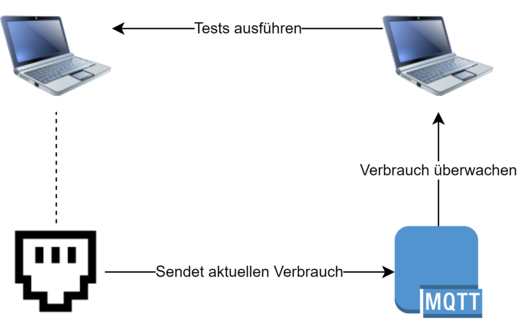
Unser Szenario ist einfach: wir wollen eine Liste von Daten übertragen. Dazu gibt es einen Server und einen Client. Die Daten sind eine große Liste, welche ein paar Zahlen und ein paar Strings enthalten. Wir haben diese Nutzlast als angemessen empfunden, denn viele „echte“ Schnittstellen sehen ähnlich aus.
Wir haben uns entschieden, den Datensatz viele tausend Male abzurufen. Da wir unsere Lösung in Java entwickelt haben, können wir so auch die Optimierung durch die JVM zur Laufzeit berücksichtigen.
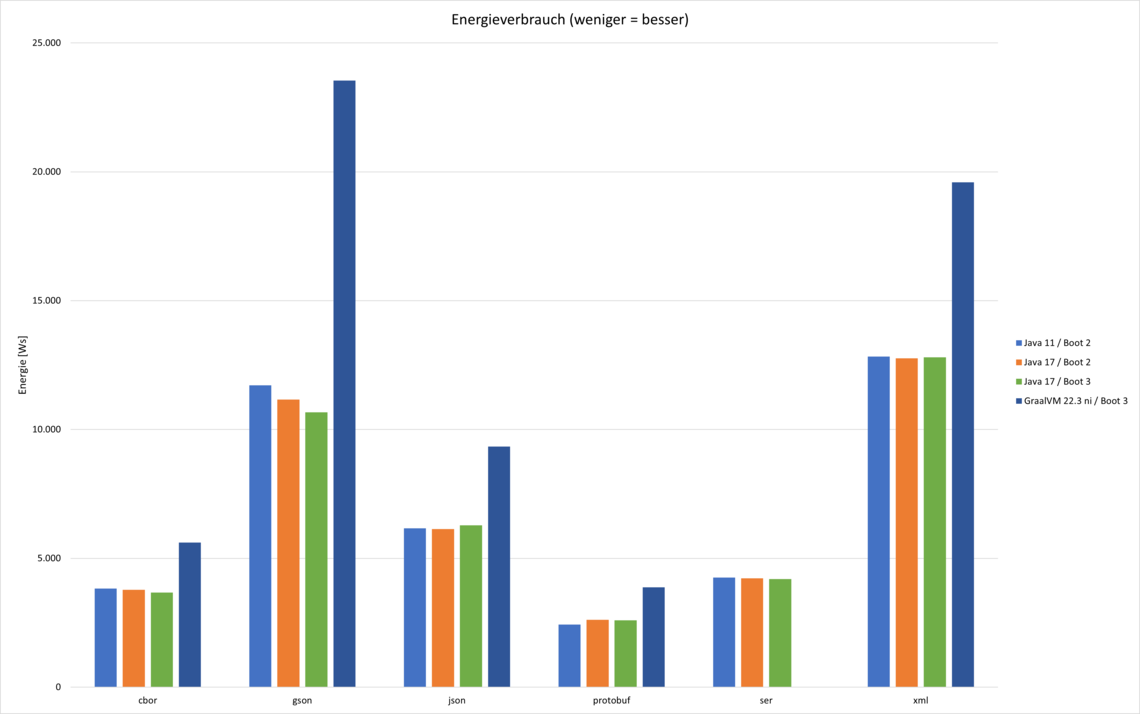
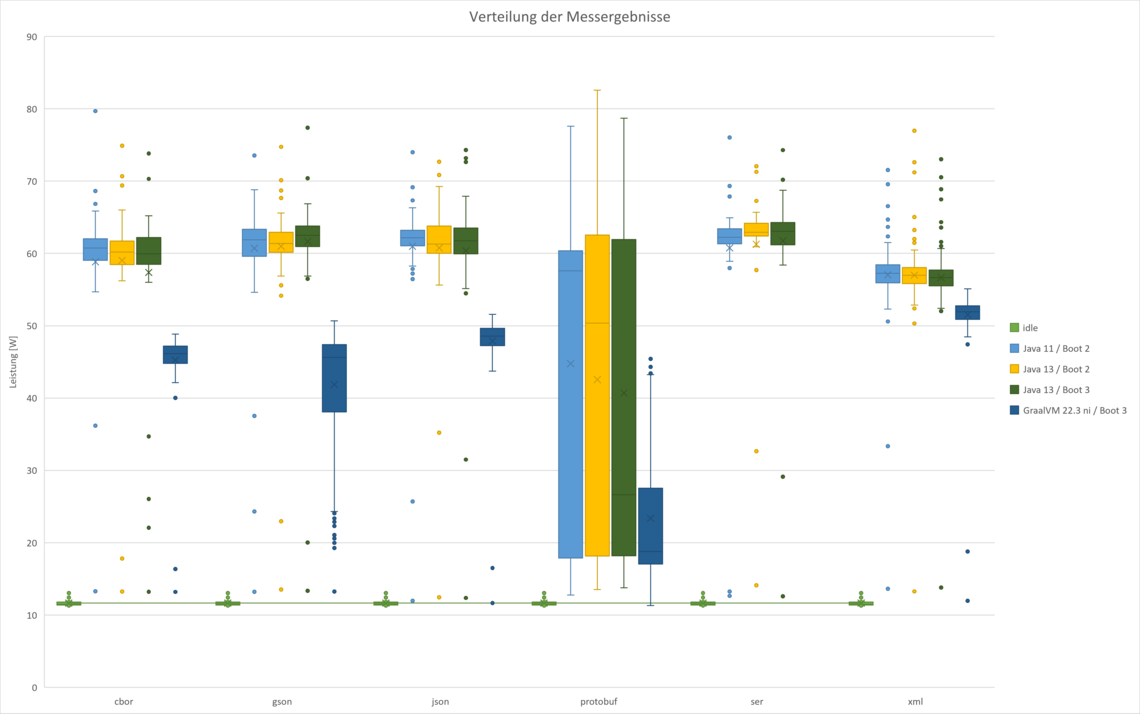
Messen wollten wir neben der reinen Zeit auch den Energieverbrauch. Eine kritische Betrachtung über die allgemeine Gültigkeit solcher Ergebnisse soll dabei nicht fehlen.