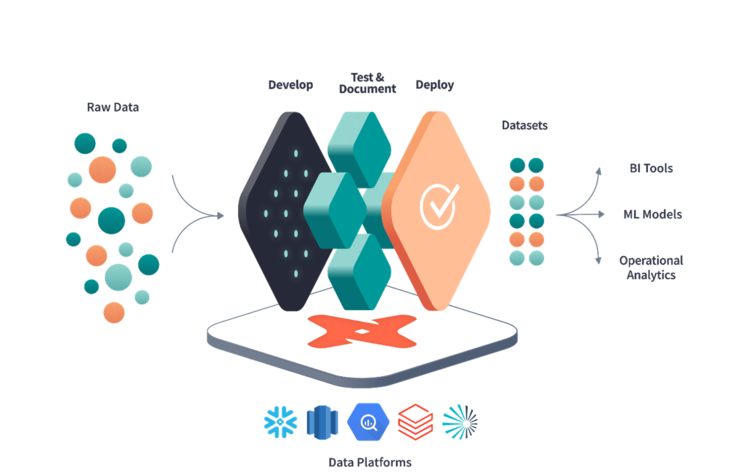
Die Probleme beim Betrieb einer modernen Datenplattform, z.B. in Form eines Data Lakes oder eines agilen Data Warehouses, sind vielfältig. Oftmals liegen Daten nur in ihrer Rohform vor und die Data Engineers, die für die Transformation von Rohdaten in auswertbare Daten verantwortlich sind, arbeiten an vielen Themen gleichzeitig. Dies sorgt für Verzögerungen beim Einbinden neuer Datenquellen und als Folge für Frustration bei Analyst*innen oder Dashboard-Developern, die die neugewonnen Daten für Visualisierungen verwenden möchten.
Das Data Build Tool (dbt) hilft diese Probleme zu lösen, indem es z.B. Analyst*innen ermöglicht, selbst die nötigen Transformationen zu implementieren. Dies macht zeitaufwendige Abstimmungen zwischen Data Engineers und Analysts bzgl. Unternehmenslogik obsolet und verkürzt die Time-To-Deliver für neue ETL-Pipelines. Durch den Einsatz von dbt werden die Verantwortlichkeiten für Transformationen in einer Datenplattform klarer getrennt und eine bessere Organisation geschaffen.