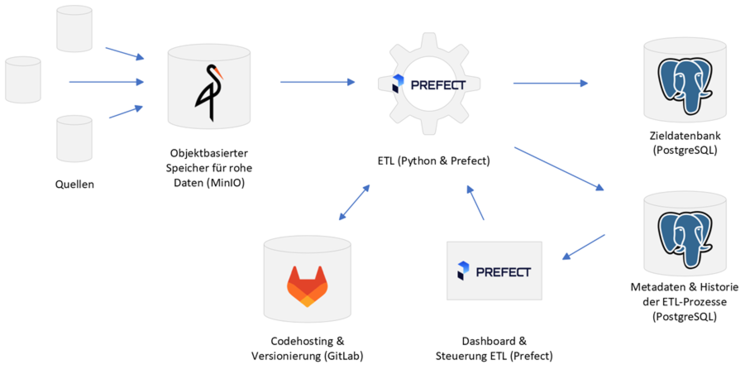
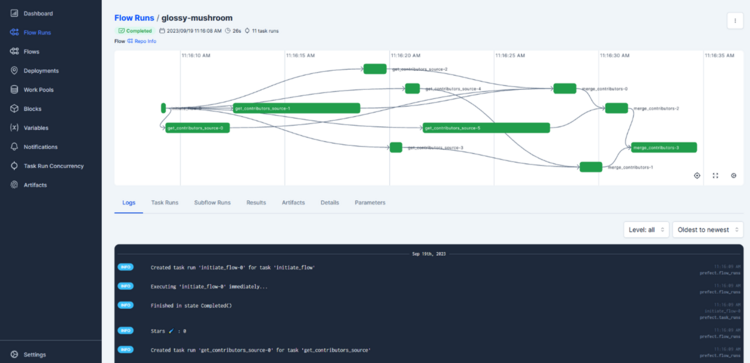
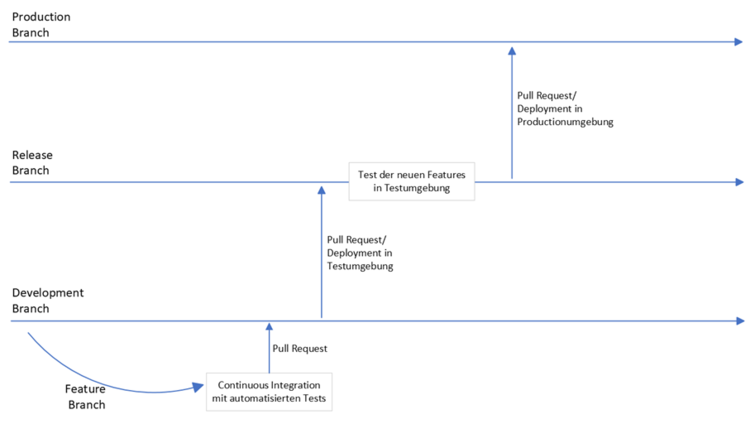
Unser Beispielprojekt sieht so aus: Unsere Daten liegen in relationalen Datenbanken dezentral an diversen Zweigstellen in Deutschland, möglicherweise in variierenden Formaten. Wir wollen diese Daten zusammenführen und mit bereits zentral vorhandenen Daten verbinden um sie ganzheitlich nutzen, auswerten und vergleichen zu können. Gleichzeitig soll sich der Prozess für die Zweigstellen möglichst simpel gestalten.