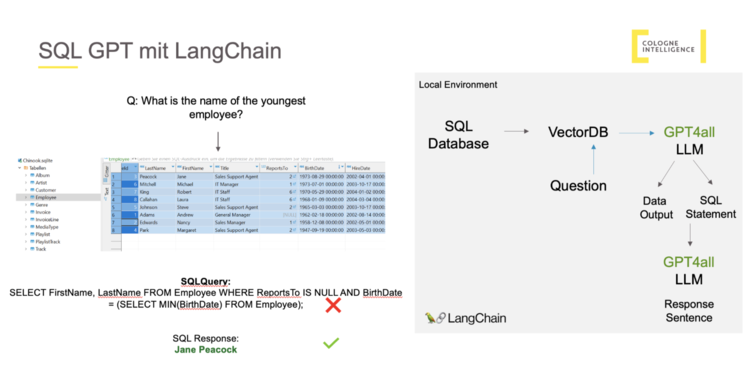
Künstliche Intelligenz hat bei CI schon lange Bestand und ist in vielen Bereichen unseres täglichen Arbeitens verankert. Unsere KI-Expert*innen sind alle in unserem Data Science-Team beheimatet. Nichtsdestotrotz hat der CI Hackathon 2023 auch einer Gruppe von fachfremden Kolleg*innen die Möglichkeit gegeben das Thema experimentell zu erforschen. Das Schlagwort KI hat gleich acht Menschen angesprochen und zusammengebracht. Unsere Erkundung der KI-Welt begann mit einem einfachen und doch spannenden Ziel vor Augen: Wir wollten die KI nach bestimmten Regeln und Informationen fragen, die in Spielanleitungen zu Gesellschaftsspielen, wie Siedler von Catan oder Paleo verfügbar sind. Unser Anspruch war hoch – wir wollten, dass die KI nicht nur einfache Fragen beantworten kann, sondern auch knifflige und komplexe Anfragen versteht und adäquat reagiert. Durch den schnellen Fortschritt mit guten Ergebnissen in den ersten Stunden, entstanden in unserer Gruppe neue Ideen, die wir nach einer gemeinsam erarbeiteten Basis in kleineren Gruppen parallel erforschen wollten. Zum einen wollten wir herausfinden, wie gut sich die KI für Anfragen zu Confluence-Inhalten nutzen lässt und zum anderen ob sie sich auch für SQL-Datenbank Anfragen eignet.
Die Exkurse können von den Leser*innen übersprungen werden, sie enthalten mehr Informationen für das technische Verständnis.