Wie lernt eine AI?
In den meisten Fällen wird eine AI auf einem bestimmten Datensatz trainiert. Das heißt, ihr wird eine möglichst große Anzahl an Beispielen gezeigt und sie versucht nun, anhand dieser Beispiele Gemeinsamkeiten abzuleiten, um eine Entscheidung zu treffen. Hierbei wird eine vorher definierte Zielfunktion minimiert, welche dafür sorgen soll, dass die AI ein passendes Verhalten erlernt. Dies hat folgende direkte Implikationen:
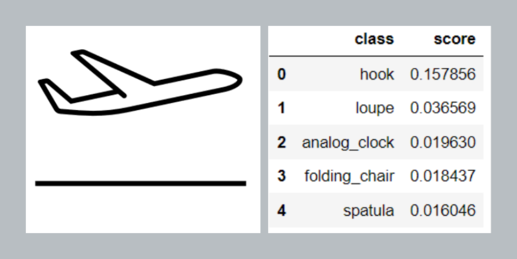
- Eine AI lernt, was die Zielfunktion am stärksten minimiert. Somit lernt sie oft die einfachsten Unterscheidungskriterien. Dies müssen nicht logische Kriterien sein, sondern können auch zufällige oder ungewollte Zusammenhänge in den Daten sein.
- Eine AI lernt Zusammenhänge anhand der Verteilung der Daten. Liegen hier Ungleichgewichte vor, so lernt die AI, diese wiederzugeben. Ändert sich die Verteilung, so können die Ergebnisse der AI schlechter werden.
Bei beiden Punkten spielen die Daten eine entscheidende Rolle. Sind sie allgemein genug, so dass die AI die relevanten Unterscheidungsmerkmale erlenen kann? Sind sie ausgeglichen genug, so dass die AI bei allen Teilaspekten ein gutes Ergebnis liefern kann? Oder beinhalten die Daten etwa ein Bias, eine systematische Verzerrung, welche zu einem ungewünschten Verhalten führen kann?