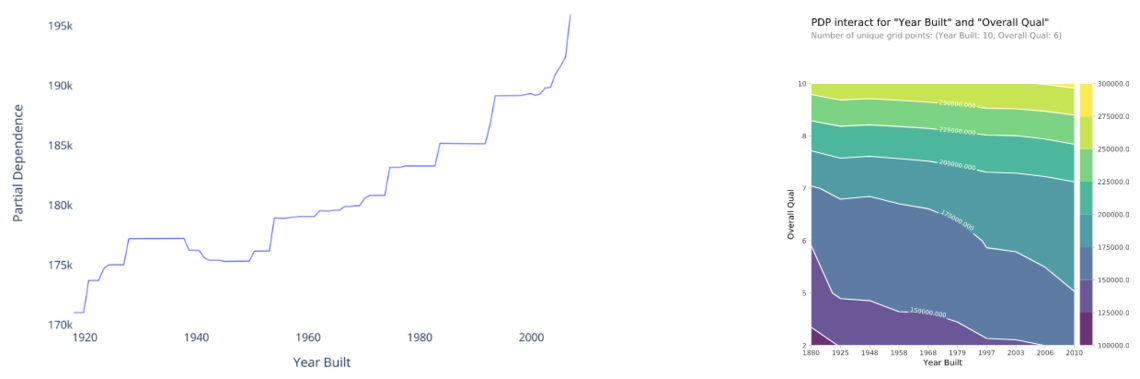
Darum ist Explainable AI so wichtig
Machine Learning (ML) ist in den vergangenen Jahren als Prognosewerkzeug immer mehr in den Vordergrund gerückt. Sowohl in der Wissenschaft als auch in der freien Wirtschaft finden sich immer mehr Anwendungsfälle für Machine Learning Modelle. So lassen sich beispielsweise Moleküle auf ihre biologischen Eigenschaften hin klassifizieren [2], oder Techniken für das autonome Fahren entwickeln [3]. Aber auch Use-Cases wie die automatische Erkennung von Betrugsfällen oder das automatisierte Verarbeiten von Dokumenten lassen sich über Machine Learning Methoden abbilden [4, 5]. Dabei kristallisiert sich der Trend heraus, dass die Performance der meisten ML-Modelle sich proportional zu ihrer Komplexität verhält. Die bisher als State-of-the-Art betrachteten ML-Modelle aus dem Bereich Natural Language Processing (NLP) sind riesige neuronale Netze mit bis zu 175 Milliarden Parametern [6]. Dieses Maß an Komplexität verbietet jeglichen Versuch, die inneren Vorgänge eines solchen Modells in Bezug auf seine Vorhersagen detailliert und nachvollziehbar aufzubereiten. ML-Modelle haben auch deshalb häufig den Ruf einer undurchsichtigen Black Box inne. Hier kommt das Forschungsfeld „Explainable AI“ ins Spiel.