Time Series Analyse
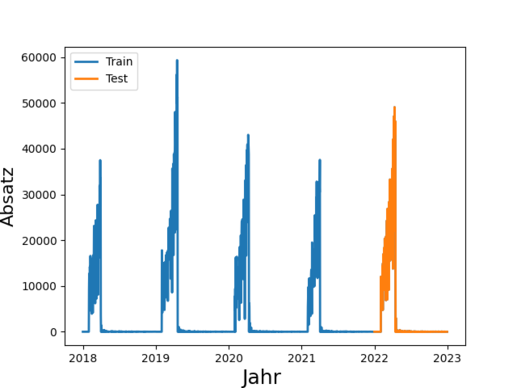
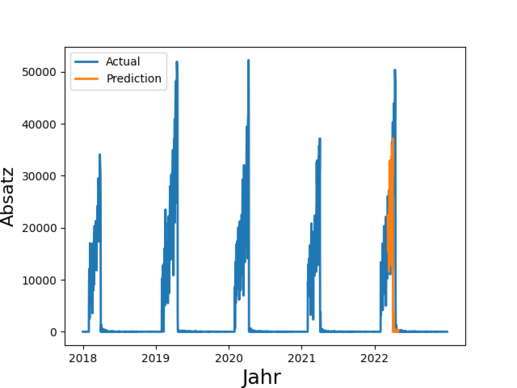
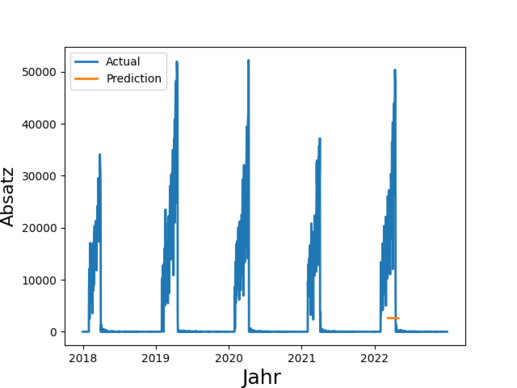
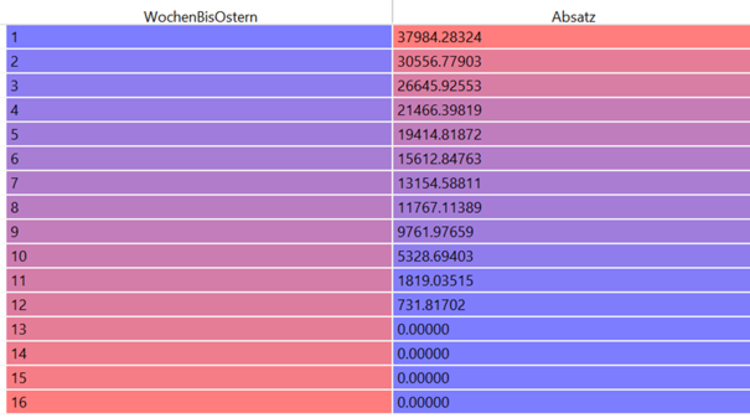
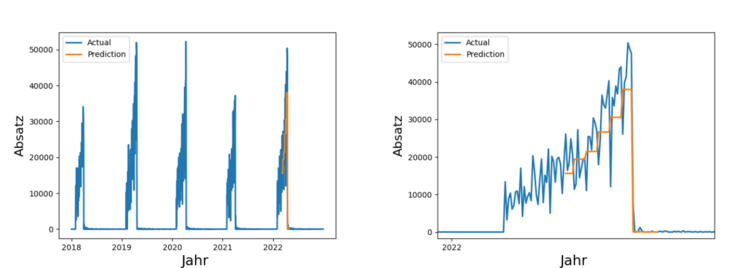
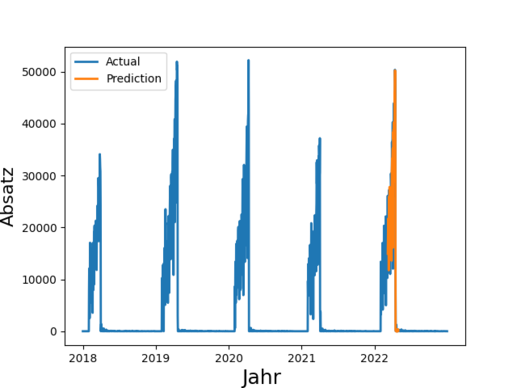
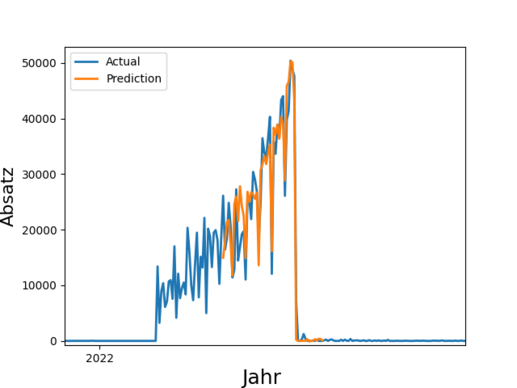
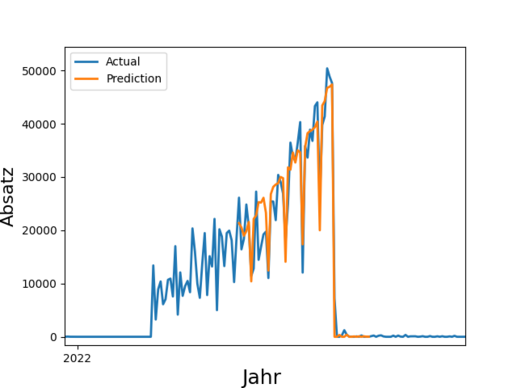
Insgesamt 4,1 Millionen Tonnen Lebensmittel entsorgt die deutsche Lebensmittelindustrie (Produktion, Verarbeitung, Groß- und Einzelhandel) jedes Jahr. Das ist wenig nachhaltig und zudem kostenintensiv. Durch eine bessere Vorhersage von Absatz und Nachfrage ließe sich Überproduktion reduzieren und dabei auch noch Kosten sparen. Derartige Prognosen sind eines der Anwendungsfelder von Time Series Prediction. Die Technik basiert auf der Analyse vergangener Zeitreihen und deren Prognose in die Zukunft.
In der Praxis werden derartige Prognosen häufig manuell erstellt und stark abstrahiert, denn eine manuelle Absatzprognose für z.B. 100 Filialen zu je 1000 Artikeln ist sehr anspruchsvoll. So werden Forecasts beispielsweise auf Ebene von Artikelgruppen oder auf Region durchgeführt, obwohl granulare Daten verfügbar wären.
Dieser Blogartikel soll einen Überblick über Machine Learning Methoden geben, die für komplexe Zeitreihenanalysen zur Verfügung stehen und einen Eindruck davon vermitteln, was deren Möglichkeiten und Grenzen sind. Die dargestellten Methoden sind dabei selbstverständlich nur eine Auswahl der vielen Ansätze, die sich und die folgenden Kategorien unterteilen lassen:
- Naive Verfahren
- Statistische Verfahren
- Klassisches Machine Learning
- Neuronale Netze